In this my very first blog after a few years, I will describe my experience of changing Airflow executor from Celery to Kubernetes. Mainly about how to change Airflow configuration, changes in worker deployment on k8s, role of scheduler in k8s executor.
Currently we are using Airflow on AWS EKS Kubernetes cluster and everything is deployed with a custom helm chart. This helm chart is a simplified version of few open source airflow helm charts that I have investigated and combined together. The idea was to get rid of many extra conditional components and features in official airflow helm chart and similar projects had to provide for many use-cases. Since we do not have to support multiple executors or multiple ways to mount dag files, different cloud providers or ingress types etc, half of the code could be deleted. It was quite hard to read and follow the helm chart templates for k8s and helm beginners, but now we have these template files with only necessary content in them;
- deployment webserver
- deployment scheduler
- deployment worker
- service account
- service
- secrets
- ingress (ALB)
- configmap (contains airflow.cfg)
- and helm's Chart and values.yaml
Using Helm values.yaml file to pass a lot of environment variables for AWS IAM role, DB info, Security groups, certificates, container cpu/memory limits, we are able to deploy this project into 4 seperate AWS accounts for software development lifecycle purpose. Sandbox environment is where I test this switch from Celery to Kubernetes executor and also regular Airflow version upgrades before deploying to development environment and later to other envs.
Limitations of CeleryExecutor
Celery executor is good enough and performant that you can use it forever if you do not have specific requirements which can benefit from KubernetesExecutor. You can read about a comparison in airflow doc in here, I will mainly write about the cases which apply to our Airflow usage.
Number of always on Airflow worker containers
Usually a higher concurrency capacity is required when you have a lot of dags and they run around the same hours or maybe constantly multiple times a day in your airflow installation, you will need to keep high number of workers online 24/7. This will lead to a low average utilization of kubernetes node resources since cpu and memory are allocated to workers which are idle but can not be used for other pods. One workaround is to give k8s resource requests low and limits high while deploying workers but this causes unstable worker containers as you can max out available memory and get random out of memory errors for random dags at random times, so we prefered stability over cost and did not use this workaround. Another way to optimize resource is to use K8s Horizontal Pod Autoscaler and I also tried this last year, however while scaling down of number of worker pods we had some random errors and decided saving a little cost does not justify developer time spend on troubleshooting random dag failues. Now that official Airflow Helm chart has scaling using KEDA, you can also check this out.
Bigger tasks fighting for resource in Celery worker
Idealy Airflow tasks should not require a lot of cpu or memory to run but we do not live in an ideal world, so when resource hungry task instances meet on same celery worker you start to get random out of memory errors or simple SLA misses due to insufficient cpu. And this happens randomly, not every day or in a predictible way. Workaround is either to give celery workers more resources or change celery worker_autoscale parameter to a lower number so they execute less amount of tasks at the same time. But this lowers your overall Airflow capacity, so usually you will increase resources which will lead to more idle resource on idle times during the day.
There is no burst capacity when needed
Let's say a very big dag with a lot of task instances failed for today's run and fix was deployed and dag has to be retried now. 400 tasks each taking average 5 minutes to run with 10 tasks concurrency of this dag means that whole dag will take 3 hours 20 minutes to complete while users in your company are waiting for data to arrive/refreshed/etc.. This is not a nice feeling, while dag runs 3-4 hours during the night and it is not a big issue, you will want to be able to run a big dag during the day quickly while people looking over your shoulder. Usual workaround is to deploy helm chart with increased number of workers config, but hey do not forget to temporarily change scheduler parallelism in airflow.cfg and dag's concurrency value and later that day revert these changes or you will burn a lot of money for those idle workers until you remember about them. Kubernetes executor can better adapt this when scheduler parallelism is inline with maximum possible number of k8s nodes and worker resource allocation. I don't say it is silver bullet, just it will save you changing less temporary configs.
Small and Big worker choice
Currently all celery workers are same, so worker_autoscale value decides on how many concurrent tasks they will run on a container using x amount of cpu cores and y amount of memory, k8s resource request and limit. But not all our dag's tasks are same in terms of resource usage, some are just taking long time while simply polling an aws api with boto3 for 1-2 hours or even more in extreme cases. But remember because of multiple reasons mentioned above we allocated extra cpu and memory to workers, so sometimes we have just maybe %2 utilization on big buffy worker containers running for many minutes, hours in total every day. What if we could use small workers for small tasks and big workers for big and resource hungry tasks? One way to do this is using another kubernetes pod container for this task and pushing this work to a Kubernetes Pod with KubernetesPodOperator but in my opinion this is another moving part to manage. Instead of this operator, we can define multiple worker pod template yaml files and pass it to each operator's executor_config= like described in here
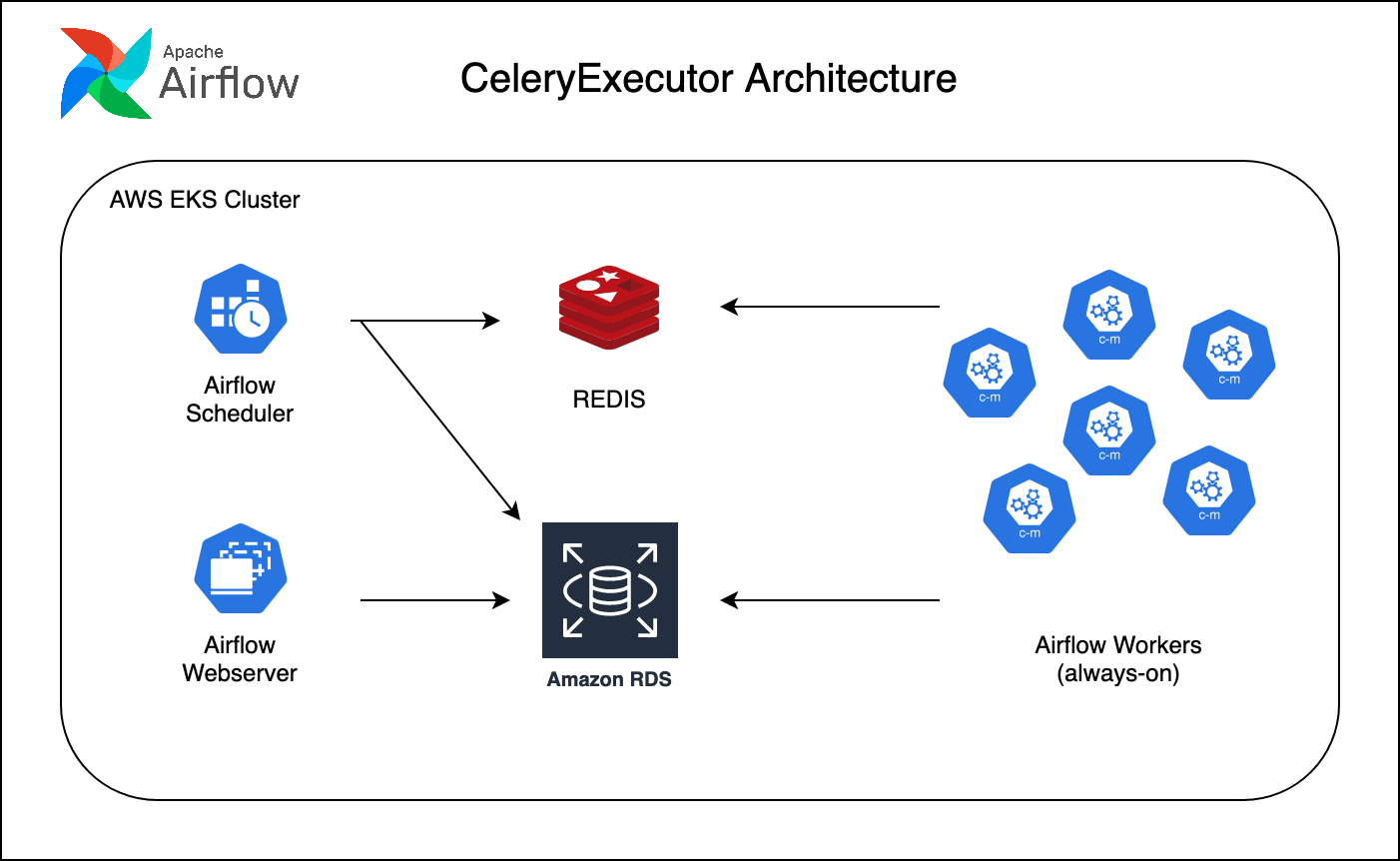
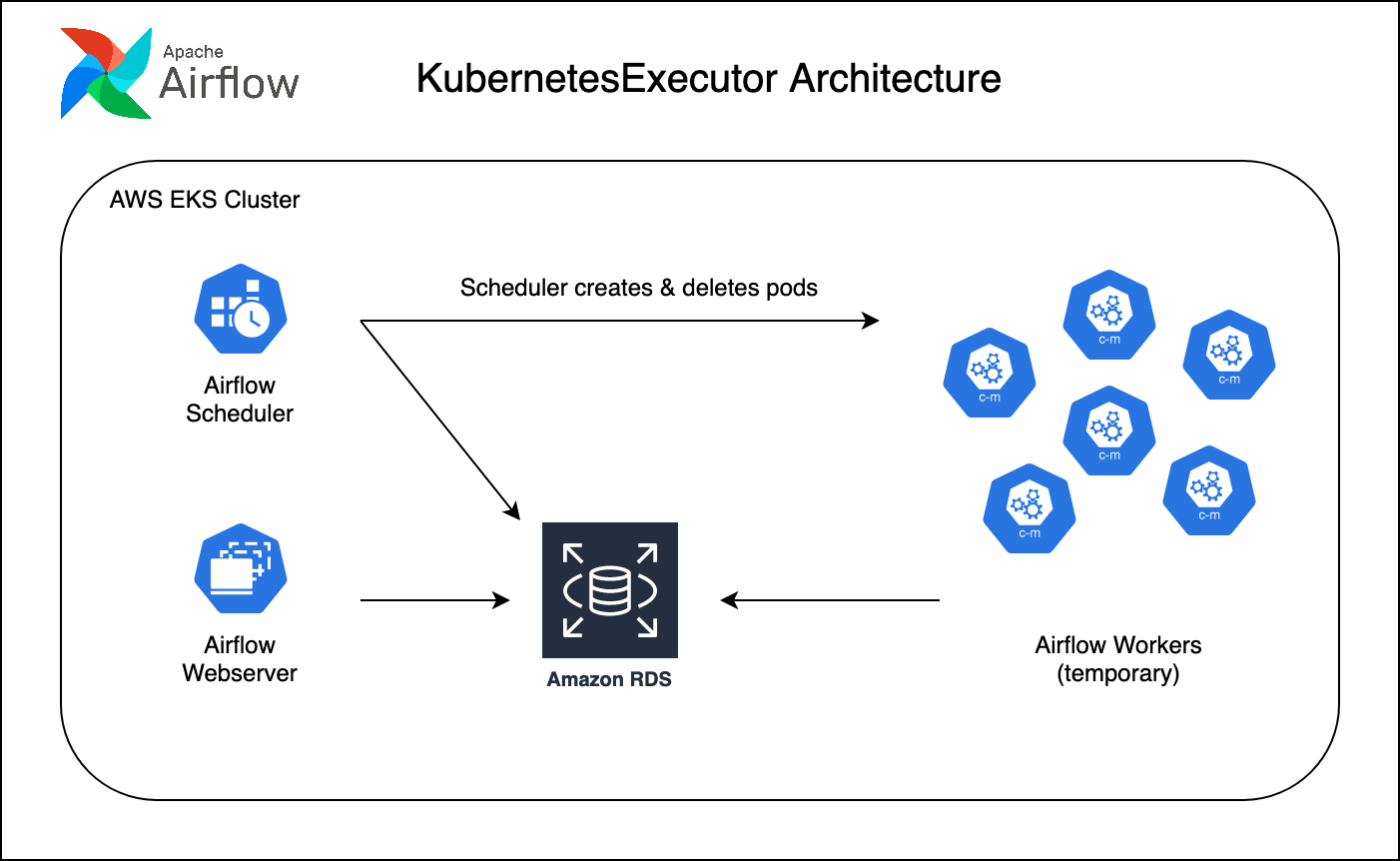
Configuration Changes for KubernetesExecutor
Here I will list changes that I made for KubernetesExecutor, based on your Airflow setup it can be little bit different.
- Install Airflow with Kubernetes dependency, so add
kubernetesfor pip install, like thisapache-airflow[....,kubernetes]=2.2.2 - Change
AIRFLOW__CORE__EXECUTORparameter fromCeleryExecutortoKubernetesExecutor - Change scheduler's
parallelismparameter value to a value based on your k8s cluster's max node limits and total resource - Give your scheduler's service account extra permissions to manage pods, like this
resources: ["pods"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- Add
kubernetessection to yourairflow.cfgfile
[kubernetes]
namespace = {{ .Release.Namespace }}
pod_template_file = /usr/local/airflow/pod_templates/worker-pod-template.yaml
airflow_configmap = {{ template "airflow.fullname" . }}-config
worker_container_repository = {{ .Values.image.repository }}
worker_container_tag = {{ .Values.image.tag }}
# If True, all worker pods will be deleted upon termination
delete_worker_pods = True
# If you want failed worker pods will not be deleted so users can investigate them.
delete_worker_pods_on_failure = False
# Note that the current default of "1" will only launch a single pod
# per-heartbeat. It is HIGHLY recommended that users increase this
# number to match the tolerance of their kubernetes cluster for
# better performance. Default = 1
worker_pods_creation_batch_size = 5
# Allows users to launch pods in multiple namespaces. Will require creating a cluster-role for the scheduler
multi_namespace_mode = False
- Create a
worker-pod-template.yamlfile. It should define your worker pod, container name has to bebaseand you should find a way to bring dag, plugin and other necessary files into this container. This can be a shared volume mount to worker container or can also be agit-syncasinit-container. Both ways are described in airflow doc in here. - Mount this
worker-pod-template.yamlfile as configmap to scheduler container on locationpod_template_fileconfig's value. - Delete your old k8s deployment file for worker, we do not need that anymore.
- Change your new worker's cpu and memory request&limit values according to your dag's requirements.
Now you can deploy the helm chart and trigger a dag. Use a tool like k9s to connect into your k8s cluster and see if Airflow scheduler can create a pod for each task instance that supposed to run. If everything works out as expected, you will see a lot of pods are being created and deleted by scheduler in your Airflow k8s namespace.
Couple of problems you can experience are;
- Pods are not getting created: Check if scheduler logs has errors related to this.
- Pods are stuck at
ContainerCreatingor similar error. Runkubectl describecommand to get k8s event logs on this pod to see error. - Some credential files are missing or worker does not have AWS IAM role: Check out pod's volume mounts and iam role annotation or service account's role annotation.
Bonus: I highly recommend to create a requirements-freeze.txt with pip freeze command file instead of normal requirements.txt to use during docker image build. Dependencies of Airflow dependencies are just too many and some get updated with breaking changes during 3 months time frame until your next Airflow version upgrade. If you are using docker image to host other config files as well, which means you need to update docker images often, then these breaking lib changes are troublemakers each time when all you wanted to do is adding one simple config file in Airflow image.